When the bookies strongly back a team to win.. and they don’t… well that’s an upset. We call this ‘choking’ [1], that is they should have won but choked under the ‘pressure’
So, which team ‘chokes’ the most, and who do they ‘choke’ against??
“Guest” (or maybe i’ll have to attribute as ‘regular’..) data visualisationist [2] Matt Dick explores this in the following post
[1] Choking, despite what Wikipedia says is not the “mechanical obstruction of the flow of air from the environment into the lungs” ;0
[2] Yes I made this job title up – however apt
Without ado:
‘
Upsets
Upsets
Matthew Dick
3/8/2016
In light of the round 2 predictions following the bookie predictions, we thought this would be a great time to start looking at bookie upsets. What I would like to do is analyse the dataset and determine if there are any common factors where the game resulted in an upset with respect to the bookies odds.
To do this, we have merged the dataset with the player information, as well as the bookies odds, model odds, predictions etc, as well as the ongoing performance of the model/bookmaker.
There is a field in the dataset, “B_FP” which indicates bookie false positives; ie. where the bookie favoured this team to win, but they did not. To further define an “upset”, I’ve picked a bookie odds cutoff of 1:1.4 (0.71). The cutoff of 1.4 is supposed to represent a strong favourite losing the game.
The total fraction of “upsets” at the 1:1.49 bookmaker odds cutoff is around 13.6% of all games.
We can have a look at the number of times each club lost when they were strong favourites.
Assuming we are happy with the volume of data being representative, lets have a look at the percentage of bookie upsets by club, sorted from highest percentage of upsets, to lowest.
Following on from this, I thought it would be interesting to see if there are certain matchups where there a particular team causes more upsets versus another. A heatmap is a convenient way to represent this, where the Y-axis represents the bookmaker favourite, and the X-axis is the opposing side. The higher the number/brighter the cell, the more often that opponent causes upsets versus the favourite side.
For example; when the warriors have been picked as strong favourites against the Dragons, the Dragons have still won all match-ups analysed (all 2 times!).
Could a reasonable staking strategy be formed around taking a punt on the Dragons in a case like this? The Dragons odds for this game (excluding the Vig) should have been at least 3:1…Or can the NRLexp model use a “choking index” as an input parameter?
After a pretty good first round of 6 out of 8 correct picks (75% accuracy) I present the round 2 predictions.
All of the picks this round are in line with the bookies so not a whole lot to say. I have included a new column indicating if the tip is in line with the bookmaker.
I have been updating the model continuously and the ‘old’ model (the one used for round 1) actually predicts St George to win against the Sharks, which would be the only game betting against the bookies.
Quick tips:
Penrith Panthers to win against Canterbury Bulldogs while Home
Brisbane Broncos to win against New Zealand Warriors while Home
Canberra Raiders to win against Sydney Roosters while Home
South Sydney Rabbitohs to win against Newcastle Knights while Home
North Queensland Cowboys to win against Parramatta Eels while Away
Cronulla Sharks to win against St George Illawarra Dragons while Home
Melbourne Storm to win against Gold Coast Titans while Home
Manly Sea Eagles to win against Wests Tigers while Away
Detailed table:
NRL 2016 R02 Predictions
Team to win
Team to lose
Preceived Probability
Perceived Odds
Implied Odds
Implied Probability
Expected Return
Kelly Fraction
Agree with bookmaker?
Tip text
Penrith Panthers
Canterbury Bulldogs
0.543
1.843
1.85
0.541
0.004
0.005
Y
Penrith Panthers to win against Canterbury Bulldogs while Home
Brisbane Broncos
New Zealand Warriors
0.658
1.519
1.5
0.667
-0.013
-0.025
Y
Brisbane Broncos to win against New Zealand Warriors while Home
Canberra Raiders
Sydney Roosters
0.615
1.626
1.72
0.581
0.058
0.08
Y
Canberra Raiders to win against Sydney Roosters while Home
South Sydney Rabbitohs
Newcastle Knights
0.649
1.541
1.35
0.741
-0.124
-0.354
Y
South Sydney Rabbitohs to win against Newcastle Knights while Home
North Queensland Cowboys
Parramatta Eels
0.587
1.704
1.65
0.606
-0.032
-0.049
Y
North Queensland Cowboys to win against Parramatta Eels while Away
Cronulla Sharks
St George Illawarra Dragons
0.63
1.588
1.5
0.667
-0.055
-0.111
Y
Cronulla Sharks to win against St George Illawarra Dragons while Home
Melbourne Storm
Gold Coast Titans
0.721
1.387
1.2
0.833
-0.135
-0.673
Y
Melbourne Storm to win against Gold Coast Titans while Home
Manly Sea Eagles
Wests Tigers
0.633
1.58
1.55
0.645
-0.019
-0.035
Y
Manly Sea Eagles to win against Wests Tigers while Away
Off to a good start! The model predicted 6 out of 8 matches for a 75% accuracy in the first round.
The two games the model mis-predicted were Manly vs Bulldogs and Roosters vs Rabbits
Assuming a $1,000 initial bank, if we used a Kelly staking strategy to bet this round, we would have made a profit of $470. Despite high prediction accuracy, the accuracy of this staking strategy would have been 50% due to its recommendation to stake on two of the matches the model actually mis-predicted.
Using Kelly staking we would have bet big on the Tigers, and this is where most of the profit comes from; however if the Tigers had of lost, we would have actually lost $483 for the round, and our final bank would have been $517!
If we had of used the (more conservative) proposed staking strategy we would be up a modest $39. Using this staking strategy we would have staked on two matches and made profit on both (100% staking accuracy).
Detailed round overview
The model predicted 6 of 8 games (75% accuracy). The models accuracy was well above the average of the 2009-2015 historic round 1 results (53%) and was well above the 2015 results (25%).
The biggest upset to the bookmakers odds was West Tigers who beat New Zealand. The bookmakers had West Tigers at 2.65 to win (indicating only a 38% chance of win).
The model was successfully in predicting two of the three upsets to the bookmakers odds (West Tigers and Gold Coast to win).
The two games the model mis-predicted were Manly v Bulldogs and Roosters v Rabbits which were upsets to the bookmakers odds as well.
Despite our high predictive accuracy for the round, If we used the Kelly strategy to stake we would have staked on four games and lost on two of the matches (50% staking accuracy). But due to the win on the Tigers we would have still made a profit.
If we had used the proposed staking strategy, we would have staked on two games and won on two games (100% staking accuracy), but due to the conservative nature of the staking strategy would have only had a modest return of $39 for the round.
Detailed simulated staking
In accordance to our staking strategy we aren’t staking on anything until round 5, but lets take a look at what would have happened if we did bet. lets assume we started with $1,000 which is the actual current bankroll in my account.
(Full) Kelly staking:
The first game we would have backed (first game which had a positive Kelly fraction) would have been Manly v Bulldogs at odds of 1.70 to win. Our Kelly fraction was 0.07 which means we would have bet 0.07*1000 ($70 dollars). Bulldogs got up in an upset win (28 to 6 – yikes!). This would have reduced our bank to $930.
The next game we would have back would have been West tigers vs New Zealand, which was against the bookies tip by a very long shot (bookies had tigers at 2.65 indicating they though they only had a 38% chance of winning). My model had them at a 60% chance of winning so the discrepancy was BIG. The Kelly fraction was 0.41 which indicates we should bet 41% of our bank on this game… hmm seems very risky, oh well I have the excuse that the algorithm made me do it! The stake would have been 0.41*930 (our new bank after the Manly loss) which is $381.
Amazingly tigers did actually get up with a 34 to 26 win. We would have won big on this game, with a profit of (2.65*$381)-$381 = $629. Adding this to our bank we would have a new bank of $1,559
The next game we would have staked on would have been Roosters v Rabbits at 2.10 to win. Roosters got smashed 42 to 10 (great work algorithm lol). Kelly stake on this was pretty high at 0.18, so we would have lost 0.18*1,559 = $281.
And our bank would have went back down to $1,278
Our last bet would have been on the Gold coast to win against Newcastle at odds of 2.0 to win. Kelly fraction for this match was 0.15 so we wold have staked 0.15*$1,278= $192. Gold coast did indeed get up (30-12) and so we would have got a reasonable return of $192 ((2.30*$192)-$192)
This would have taken our final bank to $1,470 which is a profit of $470 over our initial bank.
Proposed staking strategy:
If we were using the proposed staking strategy which is to use a fixed (5% of current bank) wager on games which have a perceived probability > than the average of the perceived probability of historic false positives, then we would have only staked on two games:
Cowboys to win against the Sharks and Storm to win against the Dragons.
We would have first staked $50 on Cowboys at 1.35 which would have given us a profit of $20 taking our bank to $1,020. We would have next staked 5% of 1,020 ($51) on Strom at 1.38. This would have given us a $19 profit taking our final bank for the round to $1,039
Obviously this is a less risk adverse strategy and in this round would have yielded a lower profit than the Kelly strategy. However keep in mind that if Tigers had of actually lost, the final bank for the round would have been $517. Such is the rollercoaster ride of the Kelly staking strategy.
Table Summary of predictions vs actual results
Tip
Score
Score Against
Result
True Positive
False Positive
Brisbane Broncos to win against Parramatta Eels while Away
17
4
correct prediction
1
0
Manly Sea Eagles to win against Canterbury Bulldogs while Home
6
28
incorrect prediction
0
1
Canberra Raiders to win against Penrith Panthers while Home
30
22
correct prediction
1
0
Wests Tigers to win against New Zealand Warriors while Home
34
26
correct prediction
1
0
North Queensland Cowboys to win against Cronulla Sharks while Home
20
14
correct prediction
1
0
Sydney Roosters to win against South Sydney Rabbitohs while Home
10
42
incorrect prediction
0
1
Gold Coast Titans to win against Newcastle Knights while Home
30
12
correct prediction
1
0
Melbourne Storm to win against St George Illawarra Dragons while Home
Only stake on games from round 5 onwards (due to models historic performance in early rounds and specific features which are driving the model precision)
Only stake on games in which the models perceived probability is greater than the bookmakers implied probability and on the condition that the perceived probability is greater than the average of the models false positive perceived probability (FPpp)
Stake using a single bookmaker (in this case Sportsbet)
Use a fixed stake of 5% of the current bank
Do not stake using any exotic bet types (such as accumulators, multi bets etc) and stake on simple head to head bets offered by the bookmaker (N.B. Sportsbet only offers head to head bets without draws (ie you cannot bet on a the outcome of an NRL match to be a draw)
The odds are NOT in your favour
Introduction
The following outlines the staking strategy I will be using for the 2016 season. The staking strategy is specifically tuned to the performance of the chosen predictive model and the detail and reasoning is presented.
This is the sad reality:
You have come up with a model (mathematic/clairvoyant or other) which can predict the outcome of matches over a season with >50% accuracy, Great! However, this does NOT mean you will be able to achieve profit. In fact it is most probable that you will lose money even if your predictive power is >50%. Although the following might come off as a little heavy on the technical speak, all I am trying to say is that in order to make a profit, you need to have a model which is able to predict winners with greater precision than the implied odds or have a model which is able to optimise staking on true positive results and mitigate staking on true negative results. This is much more difficult than simply predicting who will win a match. It also identifies one of the issues with perceived probabilities generated from machine learning algorithms – which is that they generally don’t reflect the true [*] probability of an event occurring (which is BAD if we are using these probabilities for staking).
[*] Of course no one knows the true probability of an event occurring; however some probabilities more closely reflect ‘reality’ than others
As discussed earlier, evaluation/performance measures of a two class classification model are calculated or derived using the models true positives/negative and false positives/negative results. While all of these measures are important in determining the predictive power of a model, some are of greater importance to us when evaluating if a model can generate long term profit. Specifically, when we back a team to win in a head to head match and lose, it hurts! (our dignity and wallet). In our predictive model evaluation, these instances are called ‘false positives’ (basically when the model tells us to back a team but the actual result is a loss). So it’s really important for our model to have as few false positives as possible (and of course to have as many true positives as possible). Without getting too technical, recall that the evaluation measure precision (sometimes called positive predictive value) is derived by dividing the true positives by the sum of true positives and false positives (TP/TP+FP). Because higher precision means fewer false positives this measure becomes quite predictive of how the model will perform in making a profit. In addition, because we are dealing with head to head staking (where we can only stake on the team to win), we are exclusively dealing with positive predictions (positive class = win). This means that model and staking evaluation is done primarily using true positives and false positives because there will be no true negative (and hence no false negative) results. The following outlines some simple measures one can use to evaluating if a predictive model has the potential to make profit.
Evaluating the models potential for profit
These are the facts (keeping it very simple):
For a head to head match where there are no lay bets (ie you can only back the winner):
If a bookmaker offered evens on every match (backing a winner at odds = 2.0, implied probability = 0.5) and your model had a precision across all stakes made of 50% then you would break even (profit/loss = $0)
You can only make a long term profit using a fixed staking strategy if your models precision is greater than the implied probability offered by the bookmaker over the number of matches on which you have staked (ie where the model has predicted the positive class and you have staked on its recommendation). This measure can be termed the models potential for profitability (MPP) where the higher the models precision is over the implied probability the greater the MPP.
If precision is less than the implied probability offered by the bookmaker in the same scenario, it may still be possible to make a profit using proportional staking strategies but only if the conditional potential for profitability (MCPP) is positive. If the MCPP is positive, the models perceived probabilities are said to be well calibrated. If a model’s MCPP is negative then it may be possible to (re) calibrate the perceived probabilities using regression or classification techniques.
If both MPP and MCCP are negative and the models perceived probabilities cannot be calibrated so that MCPP is positive then the model cannot make a profit
Therefore; in addition to having a model with high precision you must calculate and understand the MPP and MCPP of the predictive model utilising historic odds information. A model with high precision but negative MCPP will lose money using a proportional staking strategy.
So if MPP and MCPP are so important, what the heck are they? Well they are simple measure/s to quickly evaluate your model to determine if you can actually make money or if you need to go back to the drawing board
The measure of the models potential for profitability (MPP) can be calculated by:
Predictive models average Precision – Average Implied probability
Expressed as
MPP = mp – P(A)
where
mp = the average precision of a predictive model
P(A) = the average of the implied probability
If this is positive then you have the potential to make a profit from fixed staking. The higher this measure the greater the potential for profit (using any staking strategy). If this measure is negative then you cannot use a fixed staking strategy and expect to make long term profit
If this measure is negative, it may still be possible to make a profit IF the models conditional potential for profitability (MCPP) is positive.
The conditional potential for profitability (MCPP) can be calculated by:
(Perceived probability of true positives – Implied probability of true positives) + (Implied probability of false positives – perceived probability of false positives)
Expressed as:
(P(ATP) – P(BTP)) + (P(BFP) – P(AFP))
Where:
P(ATP) = the average perceived probability of true positive events
P(AFP) = the average perceived probability of false positive events
P(BTP) = the average implied probability of true positive events
P(BFP) = the average implied probability of false positive events
If MCPP is positive we can say that the perceived probabilities are well calibrated against the implied probabilities and there is potential to make profit utilising a proportional staking strategy even if MCP is negative. If both MCP and MCPP are negative, then the predictive model cannot be profitable. When evaluating MCP and MCPP results we can infer:
MPP positive => Potential for profit using fixed staking or proportional staking
MPP negative & MCPP positive -> Potential for profit using proportional staking
MPP positive and MCPP negative -> Potential for profit using fixed stake or proportional staking (because precision of the model will be higher than the average perceived probability)
MPP & MCPP negative -> No potential for profit
Lets have a look at how this works in practice.
MPP example
If the average of the bookmaker odds over the term of your investment is 1.67 (ie implied probability of 60%), then you need a model precision of 60% to break even. Ie if you have an MPP of 0 you will break even.
Proof:
Given:
10 matches
fixed stake (fs) of $10 on each match
odds ~1.67 (equivalent to implied probability of 60%)
MPP = 0.6-0.6 = 0. We should break even if using a fixed stake. Lets see:
Profit under the given scenario
= profit gained from correct picks (true positives) – loss from incorrect picks (false negatives)
= ((odds * fs * TP) – (stake * TP)) – (fs * FP)
=((1.67*10*6) – (10*6)) – (10*4)
=(100-60) – 40
=40-40
=0
Yup looks like it holds true.
If under the same conditions your model precision was 70% MPP would be 0.7-0.6 = 0.1. Since this is positive we expect that we will make a profit. Lets check:
profit = profit gained from correct picks (true positives) – loss from incorrect picks (false negatives)
= ((odds * fs * cp) – (stake * cp)) – (fs * FP)
=((1.67*10*7) – (10*7)) – (10*3)
=16.7
Great so all we need to do to quickly check if our model has the potential to make profit is to calculate MPP. Great! but what if MPP is negative?
Well that’s when we need to look at MCPP. This measure basically looks at the difference in our false positive and true positive perceived probabilities in reference to the implied probabilities. The idea is to determine if we can overcome lower model precision and still make profit by optimising staking on true positives and mitigate staking on true negatives.
‘The Vig’ is a hideous and foul beast, the thing of nightmares for sports punters.
The vig or vigorous, is essentially how the bookmakers are able to maintain an advantage over the average punter and (almost) guarantee a profit. It is also known as a bookmakers margin and is sometimes used interchangeably with the term overround although they are slightly different as explained below.
Let’s take the Sportsbett odds I posted for Brisbane vs Parramatta in round 1 of the 2016 season as an example. The odds (at time I posted) were 1.65 for the Broncos and 2.35 for Parramatta. Turning those odds into implied probabilities (1/odds) that indicates the bookies are giving broncos a 60.6% chance of winning and Parramatta a 42.5% winning. Hmmm…. 60.6 + 42.5 gives 103.2%. That extra 3.2% is how those sneaky buggers make their money… This 103.2% is actually termed the overround
Although it makes little difference in this example, but is important for explaining the outcome, the real value of the vig is actually (1.031-1)/1.031 = 0.31 = 3.1% and this represents the bookmakers expected profit margin.
Hers how it works in a nutshell using a simple example:
Given the odds on broncos and Parramatta, the bookmakers expect to drive the market (ie drive punters) towards betting specific proportions on the outcomes. If the bookmakers drive the market so that the proportions are equal to the reciprocal of the odds multiplied by the overround then they are guaranteed the 3.2% (vig) profit. The reciprocal of the odds multiplied by the ovveround is really just normalizing the implied probabilities to 100%
Using the figures above the proportions the bookmakers are driving the market towards are:
1/(1.65*103.2) = 0.587
1/(2.35*103.2) = 0.413
0.587 + 0.413 = 1
If they have successfully driven the market to these proportions and end up with $58.7 wagered on the Broncos and $41.3 on Paramatta (total of $100 wagered in the market) then:
If Broncos win they have to pay the punters back $58.7*1.35 = $96.9
Which means they profit $3.1
If Parramatta wins then have to pay the punters back $41.3*2.35 = $96.9
Which again means they will profit $3.1
This profit, as a % is equal to the devilish vig (3.1/100 = 3.1%)
Odds movement is all about driving the market towards these proportions so the bookmakers can make profit. In cases where the odds are close to even (2.0) then sometimes the market will drive the implied outcome. For example, if the bookmakers originally post odds in favor the Tigers to win (say 1.9 = 53% implied probability) but there is a large amount of money staked on the alternative team (say St George) to win, then they will shift the odds in attempt to realign the market towards the vig. This might mean that the original odds move, for example, to 2.2 (45% implied probability) now indicating that the bookmakers think that St George will win. In reality it is the market (ie punters) that has shifted the implied outcome.
Who is the most penalised player in in the last 10 years? What about last year (2015)?
In 2015 the titans were perceived as being the bad boys of the NRL due to their high penalty count early in the season. Was this really the case? Titans coach Neil Henry vowed to correct and reduce this. Did he?
Guest poster Matt Dick had a look at these questions and tried to answer them (with statistics of course)! Lets find out what he came up with!
‘
Chapter 1
Chapter 1
Matthew Dick
3 March 2016
Beginnings
Hi all my name is Matthew Dick and like Kane I have an interest in data science and machine learning. Kane has been kind enough to allow me to use maxwellAi as platform to share some interesting stuff about the NRL stats that he has put together. This is the first article, but i’ve had a few ideas about concepts/theories I’d like to look into regarding the historical NRL data.
Hopefully some of this can be used to help the prediction model…
I took an interest the National Rugby League (NRL) Experiment a couple weeks ago and have been putting together some player data to join up with all the round by round data Kane had already collected.
The first chapter of this data analysis vignette is a look at the data collected from the NRL website, as well as from NRLStats and AFL tables
The Data
The dataset I am working from is still a CSV (comma separated variable file) that was created by joining several thousand individual CSVs from each team and round, for seasons 2005-2015.
One of the first stats that I thought might be interesting were the penalties against each player; recorded as the “PenF” variable.
Lets see how many penalties per year there were.
season
total
2005
2264
2006
2128
2007
2547
2008
2472
2009
2317
2010
2222
2011
2132
2012
2002
2013
17
2014
0
2015
2576
Woops; looks like something is up. Either the referees weren’t looking in 2013 and 2014, or there was an issue with the data source.
Unfortunately it looks like the original data on the NRL website shows the same information. Whilst there are other sources for the penalty data, most of this is on a by game basis…and I’d like to look a little deeper.
In the meantime we’ll just have to exclude 2013 and 2014 from our analyses, until someone can help us out with the missing data (any volunteers?).
Who is the most penalised player in our data set?
player_name
total
Anthony Watmough
165
Michael Ennis
157
Johnathan Thurston
126
Beau Scott
115
Cameron Smith
115
And on an average penalties per game basis.
player_name
games
pen_per_game
Jim Curtis
2
2.000000
Ben Walker
21
1.380952
Brett Oliver
1
1.000000
Daniel Fepuleai
1
1.000000
Daniel Rauicava
2
1.000000
Not very insightful…players with low game counts are going to potentially skew our numbers.
This article mentions the Gold Coast Titans as having a reputation as the “bad-boys” of the NRL.
“It is a concern,” Henry said of the Gold Coast’s discipline.
“We were down 6-3 (in the penalty count) at half-time (against Parramatta) and talked about avoidable penalties around the ruck.”
“We’ll be looking to reduce that.”
Let's have a look at the overall average penalties per game for each club in the 2015 season, to see where the Titans sit.
Hmmm - nothing so far
They don’t seem to stand out here.
The article is dated April, which is fairly early in the season. It is possible that the Titans had a higher penalty count in the early rounds of the season. Assuming that Neil Henry had a chat to his players after round 8, we’ll look at the average penalties in rounds 1-8, and 9-26 as two separate samples.
We’ll have to exclude the byes from rounds 8 to 26 so as to not unfairly lower the average penalties for the “post chewing out” period.
Looking promising…
The mean penalties for the two parts of the season certain appear to correlate to our assumption
We can do a t-test to determine if the difference in the means is statistically significant. To do this, we have to rearrange the data a little bit.
##
## Two Sample t-test
##
## data: pen_per_game by before_after
## t = 2.491, df = 22, p-value = 0.02077
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.2302531 2.5197469
## sample estimates:
## mean in group FALSE mean in group TRUE
## 8.000 6.625
T-test interpretation
The t-test p-value of 0.02 is less than 0.05, so we reject the NULL hypothesis and conclude that the difference the means is significant.
The Titans lowered their average penalties per game after round 8 of 2015.Whether this is due to Neil Henry’s coaching, I’ll leave to the reader.
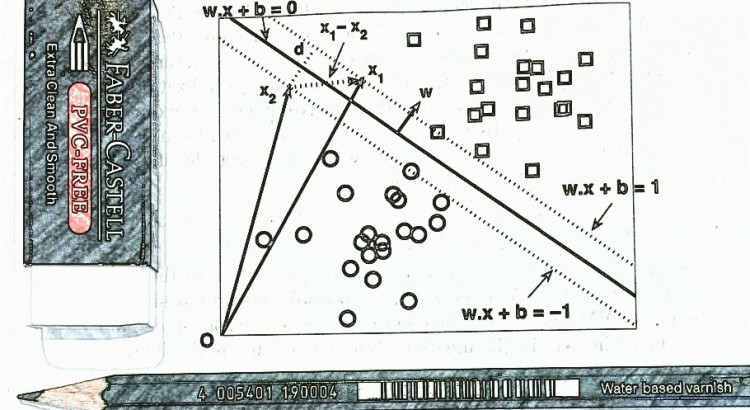
The purpose of this post is to provide details on the methodology behind the development of the predictive model (PM) which will be used for predicting the outcome of the matches of the 2016 NRL season. Additionally, it provides details on the theoretical performance of the machine learning (ML) algorithms on the 2009-2015 season data. I also outline some of the software I use to assist in creating the predictive model, however I must say that I have no affiliation whatsoever to any software vendor –I just used the software I deemed fit for my purpose due to cost and/or familiarity.
Some of the terms and concepts may be unfamiliar to the reader and where these are not listed in the glossary, I encourage you to do your own research into the terms if you are interested. In most cases I will not be delving into great detail behind the mathematics of the models, but will be providing details on the evaluation measure results for each of the algorithms. For clarification I use the term/s predictive model and machine learning algorithm somewhat interchangeably, however the difference is that; a PM is the entire prediction system whereas a ML algorithm is simply an algorithm which is initialised on a data set inside the system. For example, the PM might comprise of a system which extracts data from a database, transforms and manipulates the data into features, subsequently uses an ML algorithm on the data to predict outcomes and finally returns the results to a spreadsheet.
Summary of Method
To develop the PM, I had to do a lot of ground work, and this is not unlike any other traditional predictive modelling project. Specifically, when starting from base principles I break my predictive modelling projects down into various steps including:
Data mining/compilation/extraction
Data validation/standardisation/transformation
Analysis and (statistical) inspection of data
Feature generation
ML Algorithm generation/initialisation
ML testing and evaluation
Generation of predictive model incorporating best ML algorithm
For the NRL experiment I started from ground zero so I had to follow these steps fairly well. Specifically, I had to:
extract disparate NRL data (such as historic match results/statistics, historic bookmaker odds for all games) from a range of sources (websites, books etc.)
I used a semi-automated (programmatic) and in some cases manual process to do this
transform this data and standardise the data for input into a database
I initially compiled spreadsheets of data in Microsoft Excel and subsequently loaded into a holding database (SQL Server 2014) for further manipulation
create a database and import data into the database
I used SQL Server 2014 and Azure DB
validate and inspect the data
I used a range of software tools to assist in data inspection including R, Python, SQL programming language and Excel to plot information, produce histograms, inspect statistics of features etc.
generate features for input into ML algorithms
I used a range of software tools to generate feature including R, Python, and SQL programming language
train and program a range of ML algorithms using generated features as inputs
I used Azure ML in conjunction with R and Python to develop ML algorithms
evaluate and compare the performance of machine learning algorithms
I used Microsoft Azure ML in conjunction with R and Python evaluate ML algorithms
select the best performing algorithm and incorporate into the PM system
I use Microsoft SQL Server 2014 in conjunction with Microsoft Azure to manage the execution of the predictive model
In addition to this (and this is something I have not traditionally had to do) I had to evaluate the performance of the ML algorithms with respect to return on investment (ROI). That is, I had to ensure that I had the best performing algorithm which could also be optimized for appropriate staking on games.
In the following section/s I won’t delve into the details of the data extraction/standaridisation/validation process, or the database build process (although these are extremely important foundations steps) however I will say:
I could not find one single (free) source of information which had all of the data I wanted, and in some cases could not automate the data gathering process. Therefore, this was an extremely time consuming process and there are ultimately some features which I did not compile which may have been useful for training the ML algorithms. Of course this means that the current machine learning algorithms have the potential to get even better as time progresses and I slowly acquire more data.
Additionally, if you plan to undertake a similar experiment to me, I would highly recommend that you get familiar with and utilize a relational database management system (RDMS) such as SQL Server, Oracle database PostgreSQL or MySQL to store your data. Whilst it is possible to store all your information in spreadsheet/s there are numerous long term advantages for using a RDMS.
Data inspection and feature generation
I won’t bore you with the details behind the statistical inspection of each variable in the raw data set, although I will give you the key things you need to know. Firstly, we are analysing the compiled data from seasons 2009-2015. The number of total matches in this period is 1,608. In each season there are 201 matches played comprising of 192 regular season games, four quarter final games, two preliminary final games and 1 grand finale. The number of matches per round type has remained consistent across years 2009-2015 and the same number of matches per round are scheduled for 2016. Since the inception of the golden point rule there have only been 8 matches (0.5% of the representative data set) which ended in a draw. I determined through later predictive modelling that the chance of a draw was small enough as to be probabilistically insignificant and therefore chose to utilise binary (two class classification algorithms) for predicting the outcome of matches. The advantage of this is that binary classification algorithms tend to be much more simple than multiclass algorithms which has some computational advantage. The disadvantage is that the algorithm/s will not classify any result as a draw. It should be noted though, that the majority of bookmakers only offer head to head odds (and not odds for draw) on NRL games so it is seemingly consensus (that draws are very rare).
Also, because I only store the raw match statistics in the database (such as score, venue, match date etc.) it is necessary to create summary variables for use as input features into the ML algorithm/s. These summary features are what ultimately assist or ‘train’ the algorithm to ‘learn’ what features are important in predicting the outcome. The list of features I generated as inputs into the algorithm is presented below. Note that there are some features which I would like use as inputs which I just haven’t had time to compile. Namely things like number of cumulative penalties to date, tackles for and against, player team shifts, number of injuries leading into a match, if a ‘star’ player is playing to etc. The thing is though; if you include these features, you need them for every single game in your data set, which means I have to have a much larger database of information (if anyone is generous enough to donate info let me know!!). In reality the list of features I have is fairly limited, however as I show later, is still good enough for >0.5 prediction accuracy. The advantage of having a relatively small set of features is that they are easy to capture on an ongoing basis with limited time/resources and therefore there is some benefit in cost time analysis (how difficult is to maintain and capture information for what it ultimately gives you). Additionally as I said before, assuming some of the missing variables actual do have a positive impact on the predictive power of the algorithm, then the current models can only get better (this is what machine learning is all about)
NB:
It is very important that if you chose to create summary features like I have that you don’t summarise information which is inclusive of the current row (the current match). It seems obvious, but when you run a cumulative total in most software programs (even in excel) the cumulative total includes the current row (go check for yourself). As an example if you are creating a cumulative total of the number of matches the team has won in the last five rounds, make sure you only run a cumulative total on matches up until and excluding current game.
And without further ado, I present the feature list:
NRL Predictive Modelling feature list
Feature
Description
season
NRL season (year)
round_no
season round number
game_no
game number in the round
round_type_code
type of round (Regular, Preliminary final, Semi Final, Grand Final)
dpt_month
month number in the year the match is played
dpt_week
week number in the year the match is played
dpt_day
day number in the week the match is played
dpt_doy
day number in the year the match is played
dpt_hour
hour in the day the match is played
dpt_minute
minute in the hour the match is played
days_from_last_game
number of days since the team last played
team_descr
team description/code
team_against_descr
description/code of the against team
home_away
if the team is playing at home or playing away
venue_desc
description of the venue the match is held at
venue_loc
location of the venue the match is held at
sum_last_5_wins
the number of games the team has one in the last five matches (irrespective of season)
sum_last_8_wins
the number of games the team has one in the last eight matches (irrespective of season)
sum_season_ladder_points
the number of points the team has on the NRL ladder
sum_season_win_margin
the teams cumulative total of winning margins for the season
sum_season_lose_margin
the teams cumulative total of losing margins for the season
season_points_for
the teams cumulative scores for to date
season_points_against
the teams cumulative scores against to date
total_season_wins
the teams cumulative win total for the season
total_season_losses
the teams cumulative loss total for the season
sum_season_last_5_wins
the number of games the team has one in the last five matches (within the season)
sum_season_last_8_wins
the number of games the team has one in the last eight matches (within season)
Stay tuned for Part 02 -Generation and evaluation of ML algorithms, where the actual generation and performance of the machine learning algorithms will be presented!!
Full disclosure is that I have actually never made a bet on a game in the NRL, and in fact, I am not an avid gambler at all. Additionally, (although the majority of my family are mad keen), I don’t really follow the NRL, and rarely watch any regular season NRL games. Also, regarding other forms of sports-betting, I may have put some money in the work sweepstake for a Melbourne cup (horse racing event) or two, but generally avoid all forms of gambling (and not because of any moralistic issues, I just know that the odds of winning when uninformed gambling are very low). So actually staking on the outcome of games this year will essentially be my first foray into sports gambling.
However, I wouldn’t say I (now) don’t know anything about sports gambling or NRL. In fact, over the past six months, in order to train machine learning algorithm/s to be able to predict the outcome of games I have done an absolute inordinate amount of research in my ‘spare’ time (much to my wife’s disgust). It has been quite a learning curve; before my research my research I had no idea about historic NRL match statistics, sports betting terms or staking strategies and would say that now I could probably hold a conversation with an avid sports better.
What I did know very well before my research into sports gambling (and why I am here now), is how to extract transform and standardise disparate data, and how to create predictive models using machine learning algorithms. My foray into impending sports gambling all started because I have a formal postgraduate education in data science (although I am employed as geoscientist and not a data scientist), and when I attempt to explain to family and friends exactly what is data science, I ultimately give up and say:
‘I basically use mathematical computer models to predict stuff’
Which as you can guess, ultimately lead to the question from my ‘mad keen’ sporting friends and family:
‘can you predict outcomes of games in the NRL?’
And more importantly:
‘can we make money???’
And as you can see, I said:
‘I don’t see why not…..with some effort….’
And here I am now, I am about to put my own money where my mouth is. I am going to stake money on the games which my predictive modelling algorithm tells me to, track my progress, and see if I can actually make a profit for the 2016 NRL season!!
use machine learning algorithm/s (predictive models) to predict the outcome of every match of the 2016 NRL season with an accuracy of >0.5
stake on 2016 matches using the optimal staking strategy in conjunction with predictions made by the machine learning algorithm/s
make a profit over the 2016 season
provide best practice guidance on machine learning for sports-betting
In order to make this challenge transparent, and to enable me to track progress, over the 2016 season I will be publishing the predicted outcome (in accordance to the predictive model) of every match before each round/game. In addition I will be providing details such as the perceived probability and odds of a team winning and comparing this against the bookmakers odds. I will also be tracking the progress of every prediction and will summarise in ’roundup’ each week. Additionally I will be staking on each game in accordance with a specific staking strategy (which I will also publish) with the aim to make a season profit. Predicted outcomes, results and staking plans will all be located under the NRL Experiment posts category.
In order to undertake this challenge a lotof ground work had to be laid. The details behind the groundwork and more specifically, the theoretical performance of the machine learning algorithms can be found in ‘NRL Predictive modelling – deep dive’ and ‘Staking Strategy’, however the very high-level results of the work show that:
“the best machine learning algorithms can predict the outcome of NRL matches with 54-60% accuracy across a season”
and that:
“by using anappropriate staking strategy you could expect a return on investment of 15-20%”
It is on that basis I have chosen to proceed with the challenge and see if we can put theory into practice.
Welcome to the first round of the NRL 2016 season!
I will be posting predicted outcomes (tips) for each game of the 2016 NRL season. These predictions will be posted each week before the beginning of each round, and (time permitting) I will be posting a “roundup” on the performance of the predictions. These predictions/tips are based on a machine learning algorithm which was “trained” using historic match results from 2009-2015. Details on the evaluation and performance of the algorithm on the 2009-2015 season matches can be found in ‘NRLPredictive Modelling-Deep dive’ which I would highly recommend reading if you plan to stake on any of the predictions.
Since this is the first tipping post, I will give you a basic rundown of the table:
The table shows the team predicted to win/lose, if the team predicted to win is at home or away, and the perceived probability of the team predicted to win (note that this will always be >0.5). The table also includes the bookmaker odds, edge and Kelly fraction. Since my staking strategy this year focus’ on head to head bets only (backing who I think will win) I have left off the probability of the losing team to win (which is simply 1-perceived probability). I have included the edge and Kelly fraction for those curious (and/or who want to use this as a staking guide).
The Kelly fraction below represents the fraction of the amount of the bank you would stake on the team to win (if using a Full Kelly staking strategy). The fraction is calculated using the perceived probability and bookmaker odds by using the Kelly criterion formulae. Recall the formulae is:
(Perceived probability of team winning*(Bookmaker odds -1) -(1- Perceived probability of team losing))/(Bookmaker odds – 1)
If we use the Brisbane Broncos vs Parramatta Eels match as an example the Kelly fraction is calculated by:
(0.573*(1.6-1)-(1-0.537))/(1.6-1) = -0.139
If you were using the Kelly staking strategy in this case, even though the model predicts Broncos will win (which is in agreement with the bookmaker’s prediction), because there is no edge over the bookmaker (edge and Kelly fraction is negative) you would not place a stake on the Broncos to win. Remember this holds only for those using the Kelly staking strategy, and if you read 2016 Staking strategy you might think twice about using this strategy in full. Even though I personally won’t be using a full Kelly strategy for this seasons staking I will simulate the outcome assuming somebody did use it (just for fun ;)) and present the results at season end.
Finally, some commentary on the predictions and historic results for the first round/s:
For 2016, round 01, the model agrees with the bookmaker favourites (that is predicts the same team to win as the bookmaker) in all games except the Gold Coast, Roosters and Tigers game/s where, in contrast to the bookmaker/s the model predicts these teams to win. The largest disparity is in the Tigers vs Warriors game where the model predicts a 60.07% chance the Tigers will win, whereas the bookies predict the tigers only have a 37.7% chance of winning.
NRL S2016 R01 Predictions
Team to win
Home/Away
Team to lose
Perceived Probability
Implied Probability
Perceived Odds
Bookmaker Odds [1]
Edge
Kelly fraction
Tip
Brisbane Broncos
Away
Parramatta Eels
0.573
0.625
1.74
1.6
-0.052
-0.139
Brisbane Broncos to win against Parramatta Eels while Away
Manly Sea Eagles
Home
Canterbury Bulldogs
0.591
0.588
1.69
1.7
0.003
0.007
Manly Sea Eagles to win against Canterbury Bulldogs while Home
Canberra Raiders
Home
Penrith Panthers
0.545
0.549
1.84
1.82
-0.005
-0.01
Canberra Raiders to win against Penrith Panthers while Home
Wests Tigers
Home
New Zealand Warriors
0.607
0.377
1.65
2.65
0.23
0.369
Wests Tigers to win against New Zealand Warriors while Home
North Queensland Cowboys
Home
Cronulla Sharks
0.681
0.741
1.47
1.35
-0.06
-0.23
North Queensland Cowboys to win against Cronulla Sharks while Home
Sydney Roosters
Home
South Sydney Rabbitohs
0.572
0.476
1.75
2.1
0.096
0.183
Sydney Roosters to win against South Sydney Rabbitohs while Home
Gold Coast Titans
Home
Newcastle Knights
0.577
0.5
1.73
2
0.077
0.154
Gold Coast Titans to win against Newcastle Knights while Home
Melbourne Storm
Home
St George Illawarra Dragons
0.701
0.725
1.43
1.38
-0.023
-0.086
Melbourne Storm to win against St George Illawarra Dragons while Home